
Machine learning algorithms power numerous facilities in the world today. Here is Top 10 to know as you seek to begin your career in machine learning. At the essential of machine learning are algorithms, which are prepared to become the machine learning models Utilized to power certain of the greatest impactful inventions in the world today. Deliver to study about 10 of the greatest standard machine learning algorithms you’ll need to know, and discover the dissimilar learning Methods Utilized to turn machine learning algorithms into operational machine learning models.
In the fast-developing arena of machine learning, comprehending the correct algorithms is vital for any wishful engineer or data scientist. This article provide the top 10 machine learning algorithms that each machine learning engineer must be acquainted with to form actual methods and originate significant visions from data.
Table of Contents
Who Will Gain the Most from This Guide?
What I am giving out today is undoubtedly the greatest valued Lead I have always formed. The hint after making this guide is to abridge the journey of wishful data scientists and machine learning (which is portion of AI) enthusiasts through the world. Over this guide, I allow you to work on machine-learning difficulties and increase from knowledge. I am delivering a great-level of understanding in numerous machine learning algorithms beside with R & Python codes to run them. These must be enough to grow your hands dull. You can also check out our Machine Learning Course.
Fundamentals of machine learning algorithms with execution in R and Python, I must purposely skip the information after these techniques and artificial neural networks, as you don’t requisite to comprehend them originally. So, if you are observing for a numerical consecrating of these algorithms, you must look elsewhere. But, if you need to prepare yourself to start constructing a machine learning task, you are in for a given, particularly when it originates to software growth for startup surroundings.
3 Types of Machine Learning Algorithms

- Supervised Learning Algorithms
This algorithm contains of a target/outcome variable (or reliant on variable) which is to be expected from an assumed set of analysts (liberated variables). Supervised learning algorithms for organization and reversion include making a gathering that maps input information to the wanted outputs. By this set of variables, we make a function that maps input information to wanted outputs. The training procedure endures till the method attains the wanted level of truth on the training information.
Finest managed machine learning algorithms contain Logistic Regression, KNN, Random Forest, Decision Tree, Regression etc. All of these algorithms serve dissimilar kinds of information and problem necessities, creating them extensively appropriate through many arenas.
- Unsupervised Learning Algorithms
This algorithms work with unlabeled information, anywhere there is no target/outcome variable to expect. Unsupervised learning algorithms for gathering and information mining are intended to recognize hidden designs or structures within the information. By these designs, we group information opinions with related features, making a gathering that maps input information to clusters or groups. This procedure remains until the methods effectively identify meaningful patterns in the information.
Mutual unsupervised learning algorithms contain Principal Component Analysis (PCA), Hierarchical Clustering, and K-Means Clustering. Every of these algorithms serve dissimilar kinds of information and problem necessities, creating them extensively appropriate through numerous arenas such as pattern recognition, anomaly detection and customer segmentation.
- Reinforcement Learning Algorithms
How it functions: By this algorithm, the machine is skilled to create exact choices. The machine is visible to an atmosphere where it trains itself repeatedly by trial and fault. This machine learns from past knowledge and attempts to capture the best likely understanding to make correct business conclusions. Illustration of Reinforcement Learning: Markov Decision Procedure
Top Machine Learning Algorithms Explained
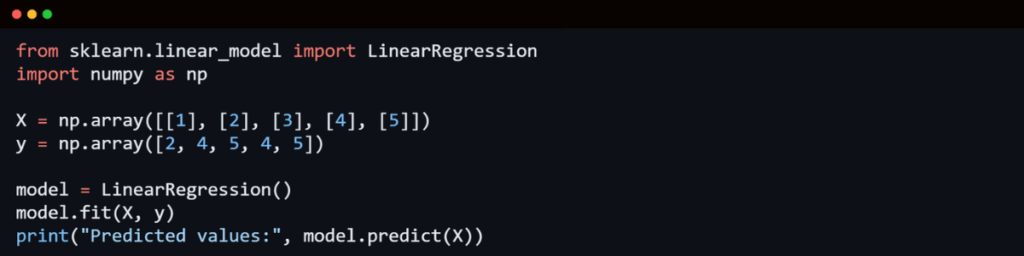
1. Linear Regression
Linear Regression is one of the simplest and most commonly used machine learning algorithms. It is used to establish a relationship between independent and dependent variables by fitting them into a straight line, known as the regression line. The equation for this line is:
Y=aX+bY = aX + b
Where:
- Y is the dependent variable (target variable).
- X is the independent variable (predictor).
- a is the slope of the regression line.
- b is the intercept.
The main objective of Linear Regression is to minimize the sum of the squared differences between the actual and predicted values. This technique is commonly used in forecasting and predictive analytics, such as sales predictions and market trends.
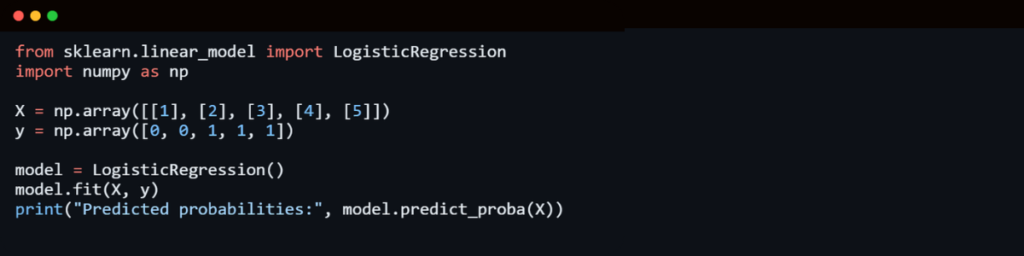
2. Logistic Regression
Logistic Regression is widely used for binary classification problems, where the outcome is either 0 or 1 (e.g., spam detection, fraud detection, medical diagnosis). Unlike Linear Regression, Logistic Regression uses a legit function (sigmoid function) to predict the probability of an event occurring.
Techniques to Improve Logistic Regression:
- Include interaction terms to capture relationships between variables.
- Feature selection to eliminate irrelevant data.
- Regularization techniques to prevent overfitting.
- Use of non-linear models for complex relationships.
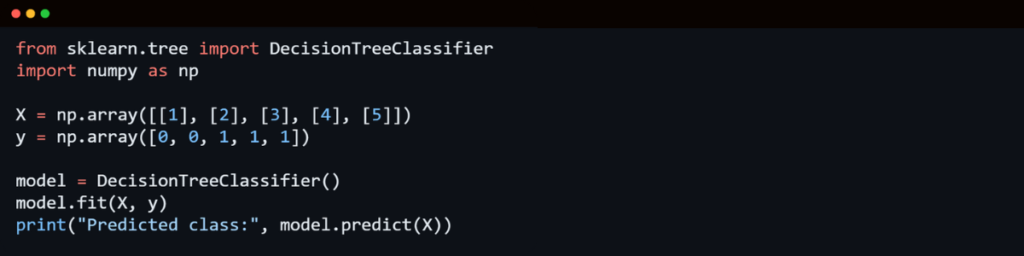
3. Decision Tree Algorithm
A Decision Tree is a supervised learning algorithm primarily used for classification problems. It works by dividing data into subsets based on the most significant independent variables.
How Decision Trees Work:
- The dataset is split into multiple nodes based on attributes.
- Each node represents a decision, leading to further splitting.
- The process continues until a stopping criterion (like maximum depth) is met.
- The final nodes (leaves) represent classifications or outcomes.
Decision Trees are highly interpretable and work well with both categorical and continuous variables. However, they can be prone to overfitting, which can be mitigated using techniques like pruning and ensemble learning.
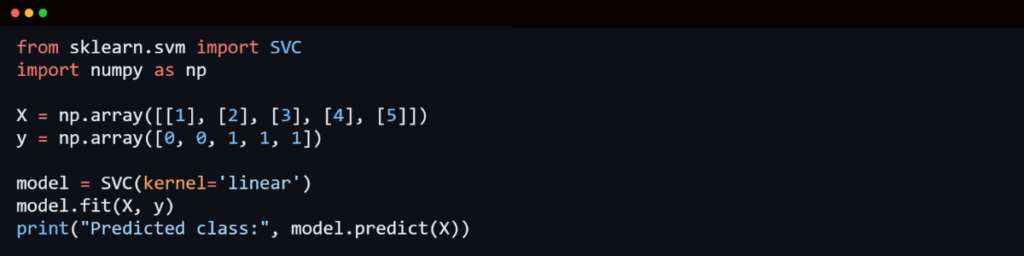
4. Support Vector Machine (SVM) Algorithm
SVM is a powerful classification algorithm that works by plotting raw data points in an n-dimensional space, where n is the number of features. It then finds the optimal hyper plane that best separates different classes.
Key Features of SVM:
- Works well with both linear and non-linear data.
- Uses kernel tricks (e.g., polynomial, radial basis function) to handle non-linearity.
Effective for text classification, face recognition, and image analysis.
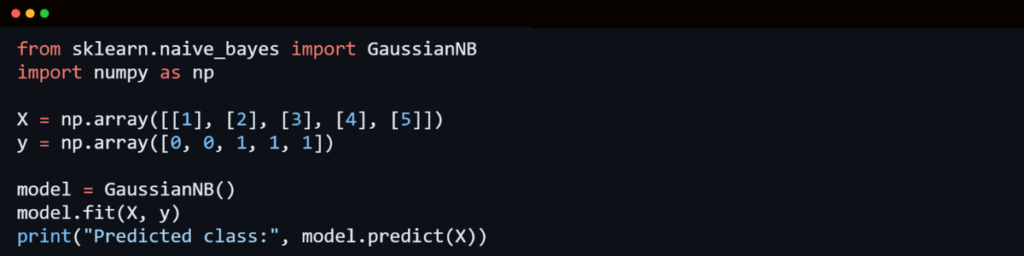
5. Naive Bayes Algorithm
Naive Bayes is a classification algorithm based on Bayes’ Theorem. It assumes that features are independent of each other, which simplifies calculations while maintaining efficiency.
Why Use Naive Bayes?
- Works well with large datasets.
- Performs well in spam filtering, sentiment analysis, and medical diagnosis.
Despite its simplicity, it often outperforms more complex models.
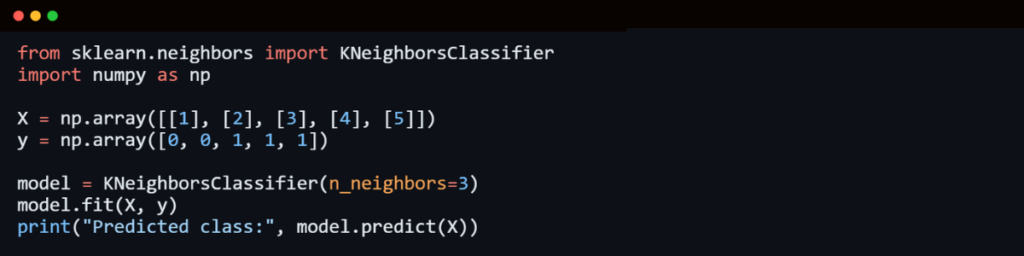
6. K-Nearest Neighbors (KNN) Algorithm
KNN is a non-parametric, lazy learning algorithm used for both classification and regression tasks. It classifies new cases based on the majority vote of their k nearest Neighbors.
Things to Consider Before Using KNN:
- Computationally expensive as it stores all data points.
- Feature scaling is required to avoid bias from larger numerical values.
- Pre-processing is essential to improve accuracy.
A real-life analogy for KNN is when someone wants to learn about a person, they ask their closest friends for insights.
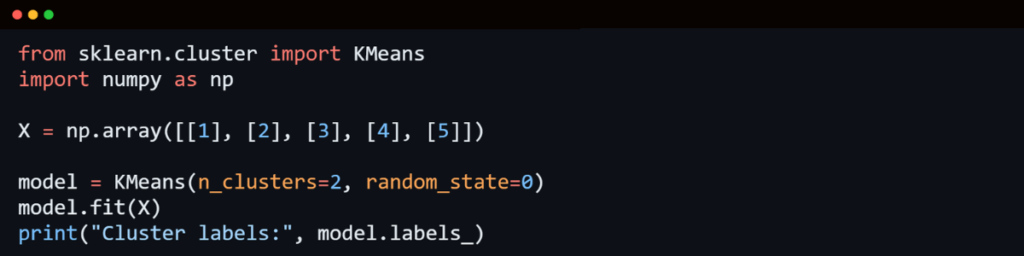
7. K-Means Clustering
K-Means is an unsupervised learning algorithm used for clustering problems. It groups data into K clusters, where each cluster contains data points with similar characteristics.
Steps Involved in K-Means:
- Choose K centroids randomly.
- Assign each data point to the nearest centroid.
- Compute new centroids based on assigned points.
- Repeat the process until centroids no longer change.
K-Means is widely used in customer segmentation, image segmentation, and anomaly detection.
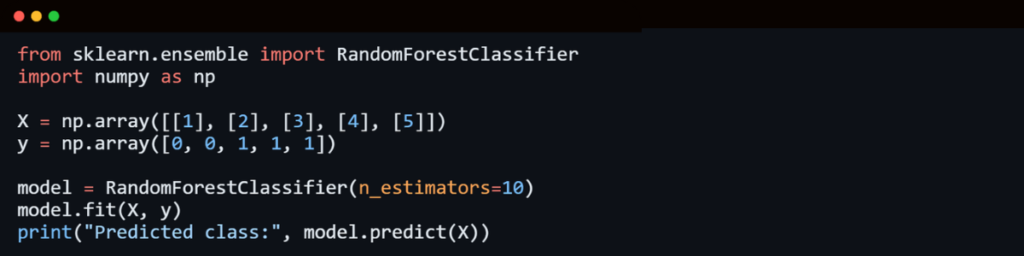
8. Random Forest Algorithm
Random Forest is an ensemble learning technique that combines multiple decision trees to improve accuracy and prevent overfitting.
How It Works:
- Random subsets of the data are used to build multiple decision trees.
- Each tree gives a prediction (vote).
- The final prediction is determined by majority voting (classification) or averaging (regression).
- Random Forest is extensively used in credit scoring, fraud detection, and healthcare analytics.
9. Dimensionality Reduction Algorithms
In modern data science, handling large amounts of data is a challenge. Dimensionality reduction techniques help in reducing the number of variables while preserving essential information.
Popular Dimensionality Reduction Methods:
- Principal Component Analysis (PCA)
- Decision Tree Feature Selection
- Factor Analysis
- Missing Value Ratio Method
These techniques help in speeding up computations and avoiding overfitting.
10. Gradient Boosting and AdaBoost Algorithms
Boosting algorithms are ensemble learning techniques that combine weak models to create a strong predictive model.
Gradient Boosting Algorithm (GBA):
- Works by sequentially improving weak models using residual errors.
- Used in regression and classification tasks.
- Adaptive Boosting (AdaBoost):
- Assigns weights to data points, giving more importance to misclassified points.
- Commonly used in image recognition and fraud detection.
Both methods are widely used in data science competitions like Kaggle and CrowdAnalytix.
Which Machine Learning Algorithm Should I Use?
Now that we have revised the key types of machine learning algorithms, it’s only usual to wonder, “Which algorithm would I use?” The response to the question varies dependent on numerous features, counting:
- The nature of data, quality, and size
- The accessible computational period.
- The insistence of the task.
What you need to do with the information.
Even a knowledgeable data scientist can’t say which algorithm will accomplish the best beforehand trying dissimilar algorithms. Beginning with these widespread machine learning algorithms is continuously a good first stage, particularly for those new to machine learning.
Comparison Table of Machine Learning Algorithms
| Algorithm | Type | Use Case | Strengths | Weaknesses |
| Linear Regression | Supervised | Forecasting | Simple, interpretable | Sensitive to outliers |
| Logistic Regression | Supervised | Classification | Probabilistic approach | Assumes linear relationship |
| Decision Tree | Supervised | Classification | Easy to interpret | Prone to over fitting |
| SVM | Supervised | Classification | Works with non-linear data | Computationally expensive |
| Naive Bayes | Supervised | Classification | Handles large datasets | Assumes feature independence |
| KNN | Supervised | Classification/Regression | Simple and intuitive | Slow for large datasets |
| K-Means | Unsupervised | Clustering | Efficient for large data | Sensitive to cluster initialization |
| Random Forest | Supervised | Classification/Regression | High accuracy | Computationally expensive |
| Boosting Algorithms | Supervised | Classification/Regression | High accuracy | Susceptible to over fitting |
Key Considerations for Selecting a Machine Learning Algorithm
Let’s discover what to reflect when creating selecting a machine learning algorithm:
- Type of Data
The major thing to look at is defining the type of data that you have. For example, labeled datasets or those with clear outputs can be delegated in the hands of overseen approaches. On the additional hand, in the situation of unlabeled data, unsupervised methods are necessary to discover hidden structures. In situations where learning is approved out through connections, reinforcement learning appears to be a useful applicant.
- Complexity of the Problem
Afterward, estimate the difficulty of the problem you are trying to resolve. In responsibilities that are less difficult, simpler algorithms can do the job. Though, if you’re undertaking a more difficult problem with elaborate relationships, you might need to usage more innovative approaches, like neural systems or ensemble techniques. Just be arranged for a bit more exertion and tuning.
- Computational Resources
One more significant element is the computational power at your discarding. Some algorithms, like deep learning methods, can be reserve-serious and need great hardware. If you’re working with restricted capitals, same algorithms like k-nearest or logistic regression Neighbors can still provide compact outcomes without placing too much strain on your network
- Interpretability vs. Accuracy
Lastly, reflect about whether you want an algorithm that’s Simpler to comprehend or one that arranges correctness, even if it’s a little of a black box. Decision trees and linear regression are usually Simpler to understand, creating them great for clarifying to stakeholders. In difference, more multipart methods like neural networks must give you well correctness but can be tougher to describe.
Explore More: Top 10 No Code AI Platforms for Machine Learning
FAQ
What is overfitting in machine learning?
Overfitting occurs when a model learns too much detail from training data, making it perform poorly on new data. It can be avoided using techniques like cross-validation, regularization, and pruning.
How does Random Forest improve decision trees?
Random Forest is an ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting.
What is the role of Support Vector Machines (SVM)?
SVM is used for classification and regression tasks, especially for high-dimensional data like text classification and image recognition.
What is dimensionality reduction techniques used for?
They reduce the number of input variables while retaining essential data features. Examples include Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA), commonly used for speeding up computations and avoiding overfitting.



